Snowflake today announced the public preview of Snowpark Connect for Apache Spark, a new offering that allows customers to run their existing Apache Spark code directly on the Snowflake cloud. The move brings Snowflake closer to what is offered by its main rival, Databricks.
Snowpark Connect for Apache Spark lets customers run their DataFrame, Spark SQL, and Spark user defined function (UDF) code on Snowflake’s vectorized query engine. This code could be associated with a range of existing Spark applications, including ETL jobs, data science programs written using Jupyter notebooks, or OLAP jobs that use Spark SQL.
With Snowpark Connect for Apache Spark, Snowflake says it handles all the performance tuning and scaling of the Spark code automatically, thereby freeing customers to focus on developing applications rather than managing the technically complex distributed framework underneath them.
“Snowpark Connect for Spark delivers the best of both worlds: the power of Snowflake’s engine and the familiarity of Spark code, all while lowering costs and accelerating development,” write Snowflake product managers Nimesh Bhagat and Shruti Anand in a blog post today.
Snowpark Connect for Spark is based on Spark Connect, an Apache Spark project that debuted in 2022 and went GA with Spark version 3.4. Spark Connect introduced a new protocol, based on gRPC and Apache Arrow, that allows remote connectivity to Spark clusters using the DataFrame API. Essentially, it allows Spark applications to be broken up into client and server components, ending the monolithic structured that Spark had used up until then.
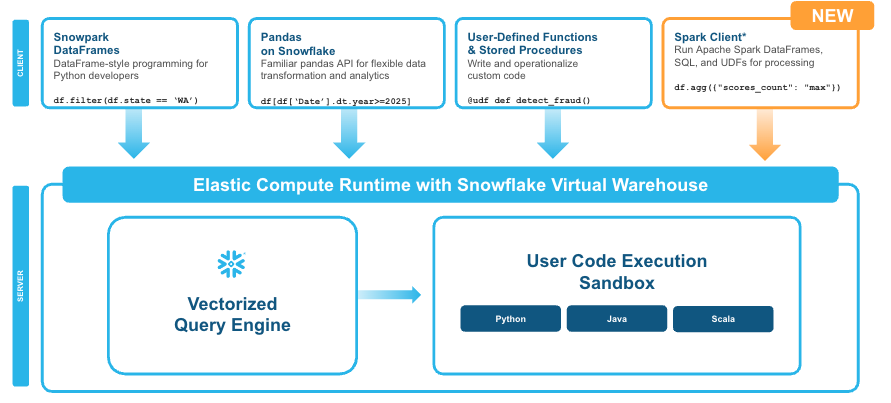
Snowpark Connect for Apache Spark lets Snowflake customers run Spark workloads without modification (Image courtesy Snowflake)
This isn’t the first time Snowflake has enabled customers to run Spark code on its cloud. It has offered the Spark Connector, which lets customers use Spark code to process Snowflake data. “[B]ut this introduced data movement, resulting in additional costs, latency and governance complexity,” Bhagat and Anand write.
While performance improved with moving Spark to Snowflake, it still often meant rewriting code, including to Snowpark DataFrames, Snowflake says. With the rollout of Snowpark Connect for Apache Spark, customers can now use their Spark code but without converting code or moving data, the product managers write.
Customers can access data stored in Apache Iceberg tables with their Snowpark Connect for Apache Spark applications, including externally managed Iceberg tables and catalog-linked tables, the company says. The offering runs on Spark 3.5.x only; Spark RDD, Spark ML, MLlib, Streaming and Delta APIs are not currently part of Snowpark Connect’s supported features, the company says.
The launch shows Snowflake is eager to take on Databricks and its substantial base of Spark workloads. Databricks was founded by the creators of Apache Spark, and built its cloud to be the best place to run Spark workloads. Snowflake, on the other hand, originally marketed itself as the easy-to-use cloud for customers who were frustrated with the technical complexity of Hadoop-era platforms.
While Databricks got its start with Spark, it has widened its offerings considerably over the years, and now it’s gearing up to be a place to run AI workloads. Snowflake is also eyeing AI workloads, in addition to Spark big data jobs.
Related Items:
It’s Snowflake Vs. Databricks in Dueling Big Data Conferences
From Monolith to Microservices: The Future of Apache Spark
Databricks Versus Snowflake: Comparing Data Giants









Leave a Reply